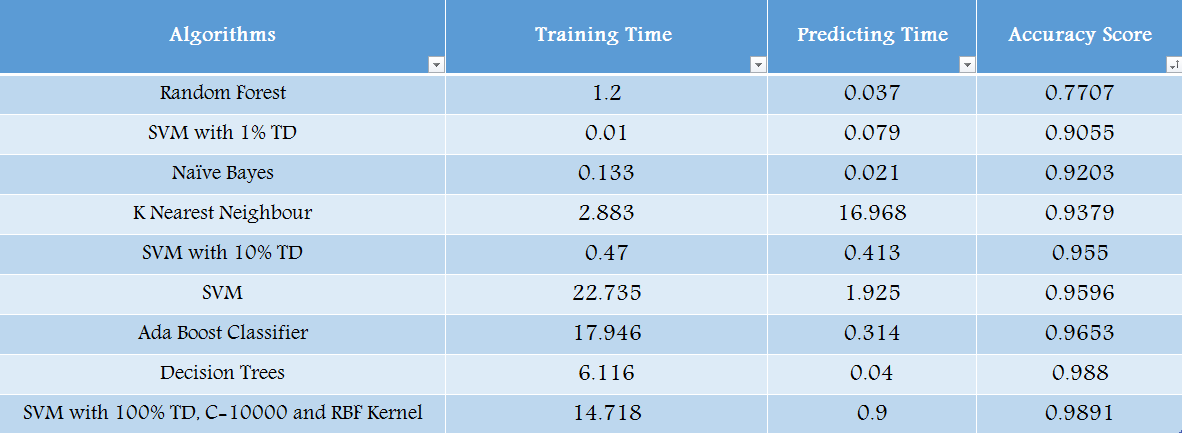
Random Forest is the go to machine learning algorithm that uses a bagging approach to create a bunch of decision trees with random subset of the data. The final prediction of the random forest algorithm is derived by polling the results of each decision tree or just by going with a prediction that appears the most times in the decision trees. Another common use of supervised machine learning algorithms is the prediction of outcomes. The model is trained to identify patterns within a training dataset, which may relate to their values or label groupings. Once the model understands the relationship between each label and the expected outcomes, new data can be fed into it when deployed.

It can then be used to make calculated predictions from the data, for example identifying seasonal changes in sales data. They seek to identify a set of context-dependent rules that collectively store and apply knowledge in a piecewise manner in order to make predictions. Machine learning algorithms are getting more advanced and starting to solve complex problems. In this blog, we discussed different types of machine learning tasks such as supervised machine learning, unsupervised learning, semi-supervised learning and reinforcement learning. It is important to get a good understanding of these machine learning techniques in order to use them effectively to solve real-world problems.
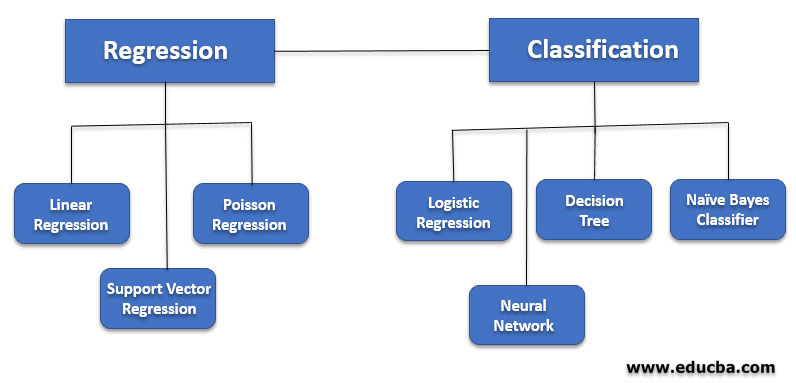
If you wanted to learn more about machine learning, there are a lot of courses available online to help you get started. Check out our channel on free online machine learning courses. Machine learning algorithms that make predictions on a given set of samples. Supervised machine learning algorithm searches for patterns within the value labels assigned to data points. Some popular machine learning algorithms for supervised learning include SVM for classification problems, Linear Regression for regression problems, and Random forest for regression and classification problems. Supervised Learning is when the data set contains annotations with output classes that form the cardinal out classes.
In case of sentiment analysis, the output classes are happy, sad, angry etc. Since the 2010s, advances in both machine learning algorithms and computer hardware have led to more efficient methods for training deep neural networks that contain many layers of non-linear hidden units. By 2019, graphic processing units , often with AI-specific enhancements, had displaced CPUs as the dominant method of training large-scale commercial cloud AI. In the introduction, we highlight the importance of applying MLA in real time. In the methodology section, we aim to give an introduction about the MLA with past and future trends, and evaluate the performance of each MLA using evaluation metrics. In the results section, a predictive model is built, and we measure the performance of that model on Iris dataset in detail.

This approach is utilized for classification as well as regression. It saves the examples, and when new data is received, it compares it to the majority of the k neighbours with whom it shares the best similarities. Unsupervised learning algorithms take a set of data that contains only inputs, and find structure in the data, like grouping or clustering of data points. The algorithms, therefore, learn from test data that has not been labeled, classified or categorized. Instead of responding to feedback, unsupervised learning algorithms identify commonalities in the data and react based on the presence or absence of such commonalities in each new piece of data.

A central application of unsupervised learning is in the field of density estimation in statistics, such as finding the probability density function. Though unsupervised learning encompasses other domains involving summarizing and explaining data features. We can utilize and harness powerful tools like Python and R to implement various types of machine learning algorithms to make the most out of the data.

Apart from that, we can also integrate these models into various end-user applications. Unsupervised machine learning algorithmsThis type of machine learning algorithm arguably represents artificial intelligence in its true form. Unsupervised ML is based on the idea that a machine can learn without any guidance from humans. For learning, it uses unlabeled data, which is basically raw data that can be found "in the wild" and is usually unstructured and unprocessed. Data visualisation models created from unsupervised machine learning algorithms can create charts, diagrams and graphs from unlabelled data. The process can take complex and unlabelled data sets and quickly plots visualisations to provide insight.
Data visualisation overlaps with clustering, as the technique visualises the different clusters of data plotted across two or three dimensions. Data visualisation makes observing and understanding the grouping of complex data more straightforward. Are drawing attention for modelling processes in the chemical and biochemical industries.

Due to a lack of fundamental understanding of complex processes and a lack of reliable real-time measurement methods in bio-based manufacturing, machine learning approaches have become more important. Since flocculation is a process that occurs across length- and time scales, an integrated hybrid multi-scale modelling framework can improve the phenomenological understanding of the process. The first-principles models utilized in this study are molecular scale particle surface interaction models such as combined with a larger-scale population balance model. A major drawback of decision tree machine learning algorithms, is that the outcomes may be based on expectations.

When decisions are made in real-time, the payoffs and resulting outcomes might not be the same as expected or planned. There are chances that this could lead to unrealistic decision trees leading to bad decision making. Any irrational expectations could lead to major errors and flaws in decision tree analysis, as it is not always possible to plan for all eventualities that can arise from a decision.

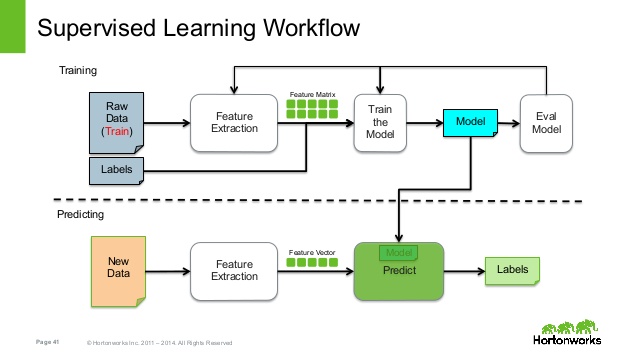
Machine learning is the study of computer algorithms that can improve automatically through experience and by the use of data. Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. In this form of machine learning, we allow the algorithm to self-discover the underlying patterns, similarities, equations, and associations in the data without adding any bias from the users' end.
Although the end result of these is totally unpredictable and cannot be controlled, Unsupervised Learning finds its place is advanced exploratory data analysis and especially, Cluster Analysis. Supervised machine learning algorithms will often be trained to classify datasets. The models will be trained on labelled datasets on how to recognise objects and their classifications.

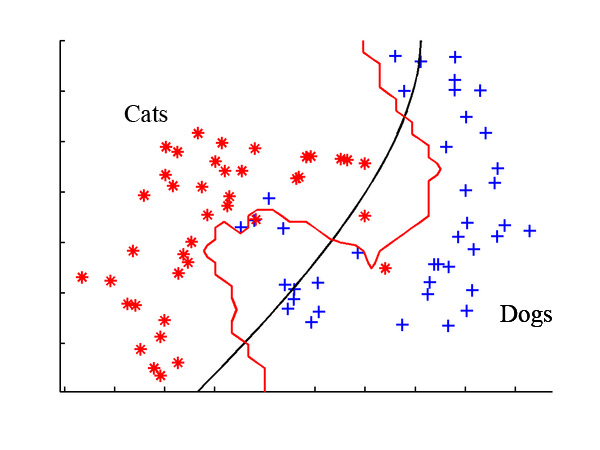
Models can be trained to classify a range of data types, such as images, text or audio. The process is supervised, as the parameters of each classification must be set by the developer. Semi-supervised learning is defined as a machine learning task that uses a combination of labeled and unlabeled examples for training. Semi-supervised learning assumes the use of both labeled and unlabeled data in order to train on, but it does not assume that all of the labels need to be provided by humans. The way to improve supervised machine learning by using unlabeled data is called semi-supervised machine learning algorithm, which can solve problems of classification, regression, clustering and association. Decision trees are a type of supervised learning algorithms, which use a tree-like branching structure to generate predictions of the target variable.

Each branch node in the tree corresponds to a specific attribute, while each leaf node corresponds to specific value of that attribute. Due to its graphical nature it is one of the easiest models to interpret. This method is very helpful in identifying the best action to take for a given decision.

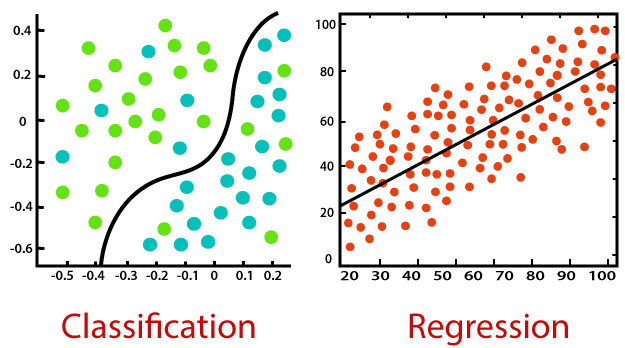
Regression, for example, is a supervised learning technique commonly used to identify relationships between variables. Another common form is called classification, in which the algorithms group data into categories, which includes linear classifiers, decision trees and support vector machines. It is a simple classification of words based on the Bayes Probability Theorem for subjective analysis of content. This classification algorithm uses probabilities using the Bayes theorem. The basic assumption for Naive Bayesian algorithms is that all the features are considered to be independent of each other. It is particularly useful for large datasets and can be implemented for text datasets.
Decision tree learning uses a decision tree as a predictive model to go from observations about an item to conclusions about the item's target value . It is one of the predictive modeling approaches used in statistics, data mining, and machine learning. Decision trees where the target variable can take continuous values are called regression trees. In decision analysis, a decision tree can be used to visually and explicitly represent decisions and decision making.

In data mining, a decision tree describes data, but the resulting classification tree can be an input for decision making. A subset of machine learning is closely related to computational statistics, which focuses on making predictions using computers; but not all machine learning is statistical learning. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a related field of study, focusing on exploratory data analysis through unsupervised learning. Some implementations of machine learning use data and neural networks in a way that mimics the working of a biological brain.

In its application across business problems, machine learning is also referred to as predictive analytics. K-means clustering is one of the simplest unsupervised learning algorithms, which is used to solve the clustering problems. In K-means, K-refers to the number of clusters, and means refer to the averaging the dataset in order to find the centroid.

As the name suggests, semi-supervised machine learning is a blend of supervised and unsupervised approaches. It combines elements of both types of machine learning algorithms. It is used with datasets that have only a portion of data accurately labelled.
These are also supervised learning algorithms that utilize the concepts of predictive analytics to classify problems to find solutions. It is utilized by businesses to help predict the probability of an event by fitting data to a logit function. It is thus also called logit regression and basically inculcates a complex 'cost function' utility in the linear regression-based algorithms . It tends to develop as a Sigmoid Function' that effectively predicts values as per probabilities. Naturally, unsupervised machine learning algorithms have a lot of limitations. As they don't have any starting point for their training, there are only a few types of tasks that they can perform.
Machine Learning Definition And Types The two major ones that we'll highlight are clustering and dimensionality reduction. This is a general learning task where we would like to make predictions in the future given new examples of input variables . If we did, we would use it directly and we would not need to learn it from data using machine learning algorithms. Decision trees, which have a tree-like structure, can be used for classification and regression. The best attribute of the dataset is placed at the root of a decision tree-building algorithm, and then the training dataset is divided into subsets.

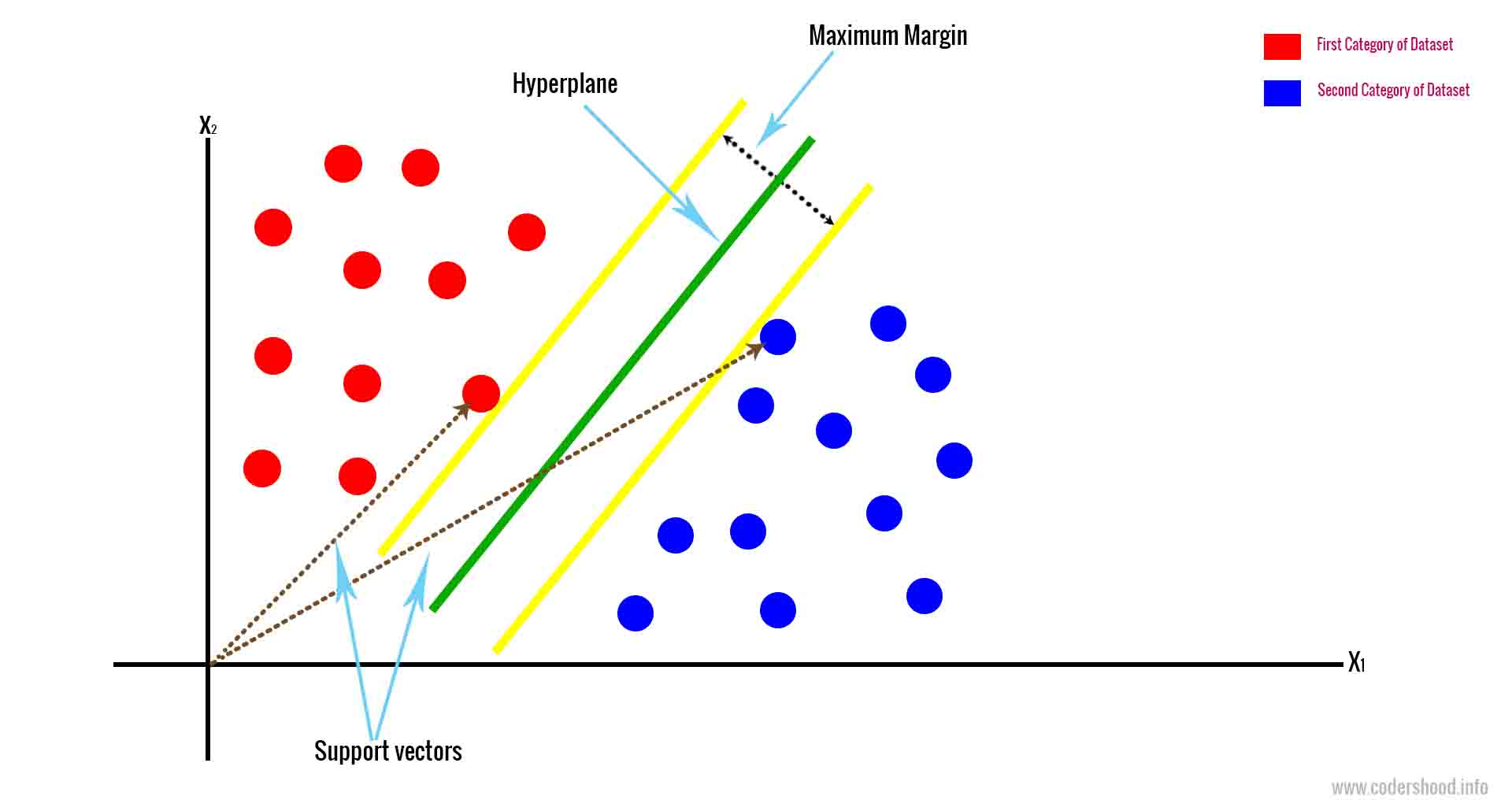
The majority of machine learning algorithms employ supervised learning methods, which are different due to labelled data with both input and output variables. Support-vector machines , also known as support-vector networks, are a set of related supervised learning methods used for classification and regression. Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that predicts whether a new example falls into one category or the other. An SVM training algorithm is a non-probabilistic, binary, linear classifier, although methods such as Platt scaling exist to use SVM in a probabilistic classification setting. Rule-based machine learning is a general term for any machine learning method that identifies, learns, or evolves "rules" to store, manipulate or apply knowledge. The defining characteristic of a rule-based machine learning algorithm is the identification and utilization of a set of relational rules that collectively represent the knowledge captured by the system.

This is in contrast to other machine learning algorithms that commonly identify a singular model that can be universally applied to any instance in order to make a prediction. Rule-based machine learning approaches include learning classifier systems, association rule learning, and artificial immune systems. Several learning algorithms aim at discovering better representations of the inputs provided during training. Classic examples include principal components analysis and cluster analysis. This technique allows reconstruction of the inputs coming from the unknown data-generating distribution, while not being necessarily faithful to configurations that are implausible under that distribution. This replaces manual feature engineering, and allows a machine to both learn the features and use them to perform a specific task.
Reinforcement learning is an area of machine learning concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward. In machine learning, the environment is typically represented as a Markov decision process . Many reinforcement learning algorithms use dynamic programming techniques. Reinforcement learning algorithms do not assume knowledge of an exact mathematical model of the MDP, and are used when exact models are infeasible. Reinforcement learning algorithms are used in autonomous vehicles or in learning to play a game against a human opponent.

Autoencoders are a specific type of feedforward neural network in which the input and output are identical. Geoffrey Hinton designed autoencoders in the 1980s to solve unsupervised learning problems. They are trained neural networks that replicate the data from the input layer to the output layer. Autoencoders are used for purposes such as pharmaceutical discovery, popularity prediction, and image processing. Hi Jason, very interesting article … I am bit of newbie … i come across "machine learning algorithms", "machine learning methods" and "machine learning models" phrases. Semi-supervised machine learning uses the classification process from supervised machine learning to understand the desired relationships between data points.
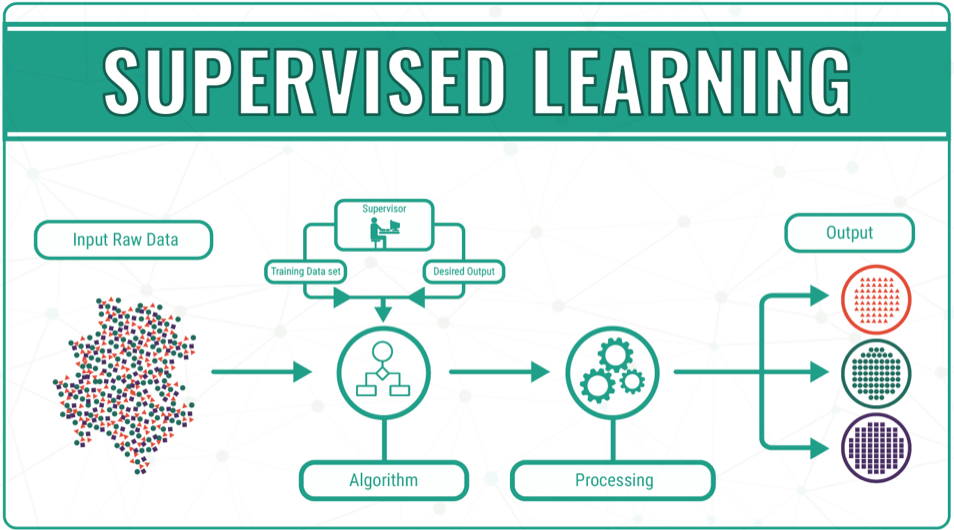
It then uses the clustering process from other unsupervised machine learning algorithms to group the remaining unlabelled data. Supervised machine learning algorithms are reliant on accurately labelled data and oversight from a developer or programmer. The algorithm is fed data which includes input and desired output defined by the developer.
The system then learns from the relationship between the input and output training data to build the model. The model maps input data to the desired output and is trained until the model reaches a high level of accuracy. Reinforcement learning is defined as the process in which machine learning algorithms are used to learn how to act in an environment so that they maximize a reward. Some real-world examples of applications leveraging unsupervised learning algorithms include customer segmentation, user profiling, fraud detection, machine quality inspection, machine failure prediction etc. A machine learning algorithm can be related to any other algorithm in computer science. An ML algorithm is a procedure that runs on data and is used for building a production-ready machine learning model.

If you think of machine learning as the train to accomplish a task then machine learning algorithms are the engines driving the accomplishment of the task. Which type of machine learning algorithm works best depends on the business problem you are solving, the nature of the dataset, and the resources available at hand. According to a recent study, machine learning algorithms are expected to replace 25% of the jobs across the world, in the next 10 years.

With the rapid growth of big data and availability of programming tools like Python and R –machine learning is gaining mainstream presence for data scientists. Machine learning applications are highly automated and self-modifying which continue to improve over time with minimal human intervention as they learn with more data. For instance, Netflix's recommendation algorithm learns more about the likes and dislikes of a viewer based on the shows every viewer watches. To address the complex nature of various real-world data problems, specialized machine learning algorithms have been developed that solve these problems perfectly. For beginners who are struggling to understand the basics of machine learning, here is a brief discussion on the top machine learning algorithms used by data scientists. As the name suggests, in case of unsupervised learning, there is no help from the user for the computer to learn.

In the lack of labelled training sets, the machine identifies patterns in the data that is not so obvious to the human eye. So, unsupervised learning is extremely useful to recognise patterns in data and help us take decisions. Unsupervised learning is also often used for anomaly detection, like to uncover fraudulent transactions or payments. This article examines essential artificial neural networks and how deep learning algorithms work to mimic the human brain.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.